近期在做另一个项目,涉及支付相关的功能。原来我主要做对公相关的业务,现在发现对私的支付手段已经日新月异,这很大程度上是由于近几年第三方支付公司的影响,对大家的支付习惯带来了很大变革。这篇文章主要介绍作为一个商户需要考虑的支付方式有哪些,每种支付方式的业务关注点有哪些。
支付从大类上分为线上支付、线下支付两大类。线上支付大家都比较熟悉,典型的场景是网上电商平台,包括京东、天猫、美团等等;线下支付大家应该也比较清楚,比如线下的麦当劳、肯德基、好利来、百货商店、一些小摊贩等。区分界限也很明确,线上就是自己不是在实体店中,线下就是在店铺内部或是面对面的情况。但现在随着各个行业互联网化的进行,线上线下的界限开始越来越模糊,有些甚至开始出现重叠。
线上支付
1.网银页面支付
顾名思义就是指的通过网银跳转的方式进行的。典型的就是在12306的网站上,选择建行卡支付,然后跳转到建行的网银支付页面,客户输入账号、密码或手机验证码,完成支付。这种支付方式只需要开通网上银行或是通过账号形式支持。这种方式除了可以跳转到各家银行的网银页面外,还可以跳转到银联、财付通、支付宝等的支付页面进行支付。
值得一提的是为了简化商户的开发成本(与不同家的网银进行对接),商户可以只与第三方支付公司对接,然后由第三方支付公司来和各家银行对接。当然了清算也是由第三方支付公司来和商户进行清算。
2.扫码支付(主扫支付)
另一种现在很流行的支付方式就是线上扫码支付,又叫主扫支付,指的是客户主动通过微信、支付宝等客户端扫码网页上的二维码来完成支付。扫码支付的流程可以参考下面的资料当面付产品介绍,需要商户系统先把订单信息发送到微信支付宝等,微信支付宝会返回对应的二维码字符串,商户将二维码转换为图片展示到界面上。二维码相关的资料我会在另一个文章中单独来写,总的来说二维码是一个字符串,各个APP会对这些字符串进行解析。
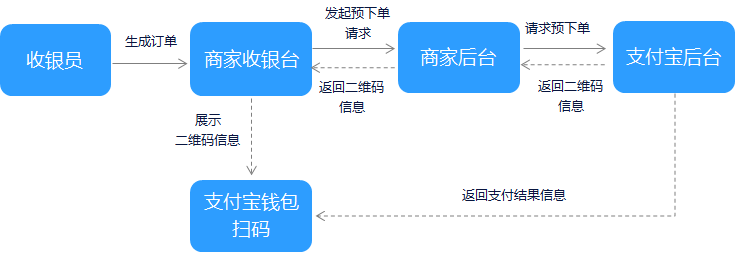
刚开始各家第三方支付公司推出的二维码之间是不兼容的,如果一个商户要支持多种支付方式,比如微信、支付宝、银联等,就需要在页面上展示多个二维码,很麻烦。为了解决这个问题,就有了聚合支付的概念,就是说一个二维码同时支持多种支付方式,如何做呢?其实也很简单,刚说了二维码本身就是个字符串,只要让这个字符串被多个支付APP认就行了,目前URL形式的字符串很多APP都可以识别。这些URL二维码微信支付宝等扫描后会展示对应的网页,这个页面一般是HTML5页面,我们可以在这个页面上提供多种支付方式,具体的话不同支付APP有不同的接口规范。这就是聚合支付的雏形,商户自己可以做这种聚合支付,也可以由专门的聚合支付提供商来做。当然了有些聚合支付商直接把自己作为一个大商户,然后再和商户进行清算,这就是二清了,这是非法的,因为聚合支付商并不具有清算的资质。
为了更进一步的规范二维码支付,银联推出了银联的聚合支付码,可以支持所有的第三方支付的APP、各个银行的APP、银联的云闪付等。这个二维码是怎么做的呢,本质上银联的二维码也是个URL,只是这个URL不是个页面,如果微信支付宝等第三支付APP扫描的话银联会返回一个跳转的URL,然后客户可以在这个URL完成支付(后续处理和聚合支付相同)。如果是银行或是银联的APP当遇到这种格式的URL会调用银联的接口对URL进行解析,解析出商户信息、订单信息,然后展示到界面上,客户支付即可。
上面说的动态二维码是有时效性的,这也是为了防止一些长期失效的订单被错误支付。
3.APP跳转支付
如果商家有自己的APP,客户在下单后选择支付就不能使用扫码二维码的方式(没法扫自己的屏幕),这时一种处理方式就是跳转到指定的支付APP,如微信、支付宝等,然后再其对应的支付页面进行支付。不同的支付APP有不同的支付SDK包及接口说明,大家可以看下。
线下支付
1.POS刷卡方式
这种是最常见的形式了,我们在商场购物可以进行刷卡,包括借记卡、贷记卡等,境内一般只要是银联的卡都可以,如果是境外的话就需要是Mastercard、VISA了。这种首先商户需要是某个银行的商户(收单行),也可以直接是银联的商户。如果刷的卡和商户收单行不同,还会涉及到银联的清算,银联会收取对应的手续费。
2.线下被扫模式
这里说的被扫是指的客户展示付款码,然后商户通过扫码枪、智能POS或是扫码盒子来扫描此付款码完成支付。这种模式也是目前比较推荐的,效率也高,更特别的是客户甚至在支付时不需要有网络。具体流程如下(以支付宝为例)
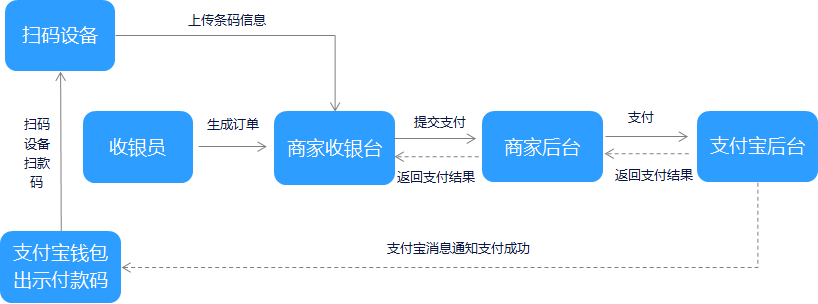
被扫模式一般是客户选择支付方式,是微信、还是支付宝,然后商家扫码,扫码后商家会把订单信息联通此付款码一并发送到微信或支付宝的后台完成扣款。
由于支付码是动态的,安全性较高,而且使用便捷,也是后续推荐的支付方式。
3.现金或扫描静态二维码
静态二维码就是现在很多小商贩上贴的二维码,微信、支付宝的。其本质是对应到某个微信支付宝的账号。当扫码时就相当于给他做了一笔转账。由于是静态二维码所以不涉及对应的订单信息,所以在支付时需要输入金额。由于静态二维码风险较高,目前人行对每日的限额已经有了限制。
4.线下主扫动态码支付
这种现在用的不多,大家应该也遇到过,在线下的时候,商户会再一个屏幕或是POS上展示一个二维码,然后由我们拿微信或支付宝来扫码。这个二维码本质上和线上的动态二维码没区别,只是展示的形式不同而已。这个动态二维码的好处是可以包含订单信息,不需要客户输入金额,而且动态码也有时效性,比较安全。
上面简单将线上线下的支付方式进行了介绍,作为一个商户不需要支持所有的这些支付方式,只要有选择的支持即可。另外由于各个渠道的支付手续费不同,通道服务质量不同,商户在收银台展示不同支付方式的时候可以有所侧重,进而引导客户的支付行为。